



TL;DR
In 2026, enterprise systems are hitting a breaking point. Monolithic architectures cannot keep up with the demand for rapid feature delivery and AI integration. Microservices provide the fix by breaking applications into independent, deployable units. However, the biggest risk is creating a “Distributed Monolith”, a system that has the complexity of microservices but the rigid coupling of a monolith. Success requires Domain-Driven Design (DDD) and a “strangler” approach to migration.
Monolith vs. Microservices: The 2026 Reality
Feature | The Modular Monolith | Modern Microservices |
Best For | Small-to-mid teams (<50 devs) | Global scale, massive orgs (>100 devs) |
Deployment | All-or-nothing release | Independent service releases |
Failure | System-wide impact | Service-level isolation |
Data | Immediate consistency (ACID) | Eventual consistency (Saga Pattern) |
AI Ready? | “Black Box” to AI agents | “Library of skills” for AI agents |
The “Distributed Monolith” Diagnostic
If you check more than three of these, you aren’t running microservices, you’re running a monolith with expensive network cables:
Deployment Coupling: You can’t deploy Service A without notifying the teams for B and C.
Shared Database: Multiple services read/write to the same tables.
Chatty Latency: A single user request triggers 15+ synchronous HTTP calls.
Version Coupling: You have a “common-utils” library that forces a global redeploy when updated.
Strategic Migration: The Strangler Fig Pattern
Stop trying to “rewrite” your app. It’s too risky. Instead, use the Strangler Fig approach:
Identify a specific business capability (e.g., Payments).
Extract it into a new service behind an Anti-Corruption Layer (ACL).
Redirect traffic to the new service.
Repeat until the legacy monolith is “strangled” and retired.
Why This Matters for AI
In 2026, we are entering the era of Agentic AI.
The Insight: AI agents (like those on AWS Bedrock) need modular APIs to function as “skills.” A monolith is a black box; a well-designed microservice is a capability an AI can orchestrate to handle complex tasks like autonomous refunds or fraud detection.
The “Two-Pizza Rule”
If your entire engineering team can be fed with two large pizzas, you do not need microservices. You need a well-organized monolith. Microservices are a solution for organizational scaling, not just technical scaling.
Executive summary
Enterprise systems are hitting limits in 2026 as monolithic architectures struggle to support rapid feature delivery, global scale, and AI‑driven experiences. Microservices offer an alternative by decomposing large applications into independently deployable services, but without disciplined design, they frequently degrade into fragile distributed monoliths rather than improving agility.
Why enterprise systems are reaching a breaking point
Enterprise applications were not built for today’s pace of change.
Product teams are under pressure to:
- Release features faster
- Support global user bases
- Scale during peak demand
- Maintain near-zero downtime
- Integrate with modern digital ecosystems
Yet many organizations still operate on tightly coupled monolithic systems where a single deployment impacts the entire application.
- A small change in billing logic may require redeploying the full platform.
- A performance issue in one module can slow down the entire system.
- Scaling for seasonal demand often means scaling everything, even the parts that do not need it.
As digital transformation initiatives accelerate across U.S. enterprises, architecture decisions have become as strategic as they are technical. They are the primary drivers of your time-to-market.
If your billing logic is tied to your inventory system, you cannot launch a new pricing model quickly. If one service failure crashes your entire checkout, you lose revenue and customer trust.
This is where microservices architecture enters the conversation.
What is microservices architecture?
Microservices architecture structures an application as a set of small, loosely coupled services, each owning a specific business capability and its own data. Services communicate over APIs or events and can be deployed, scaled, and evolved independently. This makes the approach well‑suited to cloud‑native and high‑change enterprise environments.
Microservices architecture is an approach where an application is built as a collection of small, independent services. Each service:
- Owns a specific business capability
- Has its own data storage
- Can be deployed independently
- Scales independently of other services
- Communicates via APIs or events
Instead of one large application handling everything, the system is decomposed into focused services such as:
- Order Management
- Payment Processing
- Inventory
- User Management
- Notification
Each service operates autonomously but works together to deliver the complete business workflow.
Monolith vs microservices
To understand the business impact, it helps to compare the two models.
Traditional monoliths centralize code and data in a single deployable unit, while microservices distribute functionality across independently managed services. Monoliths often offer simpler debugging and lower operational overhead. Microservices trade that simplicity for parallel delivery, selective scaling, and better failure isolation, of course, when designed and governed correctly.
Traditional monolith
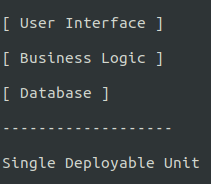
- Single codebase, shared database, one deployment pipeline, tight coupling between modules.
- Slower release cycles, higher risk during deployment, limited independent scaling, cross-team dependencies.
For many small teams, a well‑structured modular monolith remains a valid choice in 2026, especially when team size and change frequency are limited.
Microservices architecture
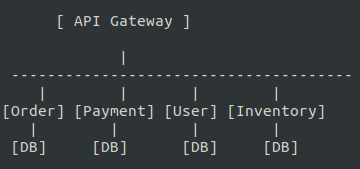
- Independent services, separate databases, independent deployment, service-level scaling.
- Parallel development, reduced deployment risk, selective scaling, greater resilience.
This architectural shift changes how product teams operate, how risks are managed, and how digital platforms evolve over time.
In modern cloud-native environments, orchestration platforms such as Kubernetes further enhance this model by enabling automated scaling, service discovery, and self-healing deployments.
However, microservices are not defined by Kubernetes. They are defined by autonomy and bounded business capabilities.
Enterprise benefits: how do microservices improve velocity, resilience, and scalability?
For enterprise product leaders, the value of microservices lies in faster delivery, better resilience, independent scalability and technology flexibility. When service boundaries match business domains, teams can ship features in parallel, contain failures to specific services and scale only the workloads under pressure. This improves both time‑to‑market and infrastructure economics.
Faster feature delivery and team autonomy
In a monolithic system, teams are tightly coupled.
A small change in one module may require coordinating with multiple teams, regression testing the entire system, and waiting for a shared release window. Microservices remove that bottleneck.
Because each service is independently deployable, teams can release features without affecting unrelated modules, work in parallel across business domains, and reduce release-cycle friction.
From a product perspective, this means shorter time-to-market, faster iteration based on customer feedback, and reduced backlog congestion.
Resilience and business continuity
In tightly coupled systems, failure can propagate quickly. A slow payment module may degrade the entire checkout experience. Microservices reduce this risk through failure isolation.
Each service operates independently. If one service experiences issues, others can continue functioning. This approach reduces system-wide outages, cascading failures, and Mean Time to Resolution (MTTR).
For enterprises where downtime directly impacts revenue, this architectural isolation becomes a strategic safeguard.
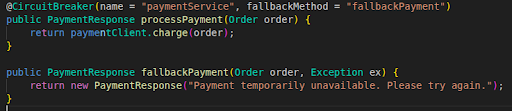
Here is how the illustration (simplified Java with Resilience4j) goes:
Independent scalability in cloud-native environments
One of the strongest enterprise drivers for microservices is selective scaling.
In monolithic systems, scaling often means replicating the entire application.
![]()
In microservices, you scale only the services under load.
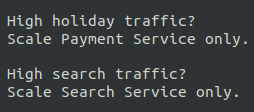
Here is the conceptual view.
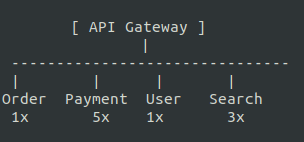
This is particularly powerful in cloud-native deployments where orchestration platforms like Kubernetes automatically adjust service replicas based on traffic.
For product owners, this translates into cost optimization, performance stability during peak demand, and better infrastructure efficiency.
Realizing these benefits requires a cloud migration cost strategy that accounts for the trade-offs between rehosting, replatforming, and refactoring – each with different implications for long-term operational economics.
Technology flexibility and innovation
Microservices allow teams to select technology stacks best suited for specific domains. This flexibility supports incremental modernization without full-system rewrites. However, flexibility must be governed carefully to avoid fragmentation, something we will address in the trade-offs section.
The 2026 risk: Are you actually running a distributed monolith?
Many 2026 microservices systems behave like distributed monoliths. where services are deployed separately but remain tightly coupled through shared databases, synchronous calls, and coordinated releases. These architectures add network latency and operational complexity without delivering autonomy. They often increase failure impact instead of reducing it.
While microservices promise autonomy and scalability, many enterprise systems fail not because of monoliths but because of poorly implemented microservices. By 2026, a more common architectural failure pattern has emerged. This is the distributed monolith.
A distributed monolith occurs when services are technically separate but remain tightly coupled in practice. Common symptoms include:
- Shared databases across services
- Excessive synchronous service-to-service calls
- Rigid deployment dependencies
- Lack of clear domain boundaries
Instead of reducing complexity, the system distributes it across network calls. In these environments, a failure in one service still impacts others, deployment coordination remains tightly coupled, and latency compounds across chained API calls. The result is operational complexity without architectural benefit.
For leadership teams, this is a critical insight. Microservices do not automatically reduce risk. Poorly designed microservices increase it.
Remember, distributed monoliths represent a significant source of hidden architecture costs that quietly erode the expected ROI of cloud modernization investments.
The 2026 operational reality – temporal coupling
The hallmark of a distributed monolith is Temporal Coupling.
If Service A cannot complete a task because Service B is down, you have not built a microservice, but a monolith with a network cable. The antidote is to emphasize Asynchronous Communication (using patterns like SQS/Kafka).
Services should emit events and move on, rather than waiting for a synchronous response from a downstream dependency. True microservices in 2026 are designed to degrade gracefully instead of crashing when a dependency is offline.
Case studies show that even modest additional latency between tightly coupled services can multiply end‑to‑end response times several‑fold. This, then, illustrates how synchronous chains amplify both performance issues and availability risks.
The distributed monolith diagnostic checklist
If you check more than 3 of these boxes, you are not running microservices, but a monolith with expensive network cables.
- You cannot deploy Service A without notifying the teams for Service B and Service C. If your services have a deployment order, they are not independent.
- Multiple services read and write to the same database tables. If you change a column name and three different services crash, you have a monolith.
- Your service dependency map looks like a tangled ball of yarn, leading to potential death spirals from a single latency spike.
- You have a common-utils library that every service imports, and updating it requires redeploying the entire ecosystem. This is Version Coupling.
- A single user request triggers 15+ synchronous HTTP calls between services. You are paying a massive latency tax.
Monolith vs microservices in 2026: a practical comparison
In 2026, many organizations choose between a modular monolith and well‑designed microservices based on team scale, domain complexity and regulatory needs. The table below contrasts how each model behaves in deployment, failure containment, data consistency, observability, and AI/API integration for modern digital platforms.
Feature | The modular monolith | Modern microservices (well-designed) |
Best for | High-velocity, small-to-mid teams (< 50 developers) | Global scale, massive engineering orgs (> 100 developers) |
Deployment model | Single release cycle (all or nothing) | Independent deployments |
Failure containment | System-wide impact | Service-level isolation |
Scaling strategy | Scale entire system | Scale individual services |
Complexity risk | Centralized (easy to trace/debug) | Distributed (requires OTel) |
Data consistency | Immediate (ACID) | Eventual (Saga Pattern) |
AI & API integration | Manual / hardcoded; a black box to AI | API-first and modular; a library of capabilities for AI |
Observability | Centralized logging | Distributed tracing (OTel recommended) |
Org. alignment | Shared ownership | Domain-based ownership |
The distinction is important.
A well-designed microservices architecture improves agility and resilience. A distributed monolith introduces operational fragility at scale.
The difference lies not in the number of services but in how they are designed and governed.
How does domain-driven design prevent microservices complexity debt?
Many failed microservices programs suffer from poor domain boundaries rather than tooling issues. Domain‑Driven Design (DDD) reduces cognitive load by aligning services with business capabilities. It also creates bounded contexts that a team can fully understand without knowing the internals of dozens of other services.
One of the primary reasons microservices fail is design, as opposed to tooling. As organizations decompose monolithic systems, they often split services based on technical layers instead of business domains. Over time, this creates a new form of risk. This is complexity debt.
Complexity debt accumulates when service boundaries do not align with business capabilities and multiple services depend heavily on each other’s internal data. Instead of enabling autonomy, the architecture introduces coordination overhead.
This form of architectural debt is a primary focus of technical debt management strategies, where AI-powered analysis helps organizations identify boundary violations before they compound into system-wide fragility.
This is where Domain-Driven Design (DDD) becomes essential. The goal of DDD is Cognitive Load Management. It ensures a developer can fit the entire bounded context in their head without needing to know how the rest of the 50 services work.
Understanding bounded contexts
Domain-Driven Design encourages structuring services around bounded contexts – clearly defined business domains with explicit ownership and responsibility. For example:
- Payment processing
- Order management
Each bounded context owns its data and defines its own language and business rules, minimizing assumptions about other domains. When service boundaries reflect business domains rather than technical components, teams gain true independence.
How DDD prevents the distributed monolith
A distributed monolith often emerges when services are separated technically but remain logically intertwined. Domain-driven design prevents this by:
- Enforcing clear domain ownership
- Reducing shared database patterns
- Encouraging event-driven integration
- Limiting cross-domain synchronous dependencies
In practical terms, DDD ensures that services communicate through defined contracts, not shared tables or implicit assumptions.
This distinction is subtle but critical. Without domain alignment, microservices increase operational complexity. With domain alignment, they unlock sustainable scalability.
For enterprise leaders, this means that microservices adoption should begin with domain discovery workshops, business capability mapping, and ownership modeling.
Technology decisions follow domain clarity, and not the other way around. Microservices are not a refactoring exercise. They are an organizational design decision.
What is a practical migration strategy from monolith to microservices?
For most enterprises, a complete rewrite is too risky. Instead, incremental patterns such as the Strangler Fig approach replace monolith functionality one domain at a time behind a stable facade, allowing new microservices to go live while legacy components are gradually retired with controlled risk.
For most enterprises, the challenge is not “Should we build with microservices?”
It is “How do we migrate safely from what we already have?”
A full rewrite is rarely viable due to risk, cost, business disruption, and loss of institutional knowledge. Instead, many organizations adopt an incremental strategy known as the Strangler Pattern.
The Strangler Migration approach
Conceptually, this involves:

- Identify a bounded business capability (e.g., payments).
- Extract that functionality into a separate service.
- Route new requests to the new service.
- Gradually reduce dependency on the monolith.
- Decommission legacy components over time.
This approach allows controlled risk, measurable ROI per domain, continuous delivery during transformation, and business continuity.
What a practical migration requires
A successful microservices transition typically includes domain-driven design workshops, architecture assessment, infrastructure readiness review, observability planning, DevOps pipeline restructuring, and an incremental rollout roadmap.
How do Anti-Corruption Layers protect new microservices?
Anti‑Corruption Layers (ACLs) sit between legacy systems and new services, translating models and contracts so that old assumptions do not leak into new domains. They act as semantic adapters. They allow teams to modernize incrementally without polluting fresh microservices with legacy data structures and workflows.
During migration, one of the most common risks is unintended coupling between the legacy monolith and newly extracted services. This is where Anti-Corruption Layers (ACL) become critical.
An ACL acts as a protective boundary between systems. It translates data models, business rules, and contracts between the legacy application and the new microservice.
Conceptually, it acts as a semantic translator. It ensures the messy logic of the old system does not leak into the new service’s clean domain.

For leadership, the ACL is your insurance policy. It ensures that the bad habits of your 10-year-old legacy system do not infect your brand-new, expensive cloud architecture.
Instead of allowing direct database sharing or tight API dependency, the ACL ensures:
- Clear, versioned interface contracts between legacy and new services.
- Explicit data transformation between legacy and modern domain models.
- Reduced propagation of legacy business rules and schema assumptions.
- Protection against future schema changes in the monolith.
Pro-tip for implementation: When strangling a monolith, consider implementing the ACL as a sidecar or a small middleware service. This keeps the core business logic of the new service pure and free from legacy translation concerns.
Migration is not just extraction. It is architectural insulation.
How do microservices make enterprises more AI-ready?
AI initiatives increasingly depend on clean APIs, modular capabilities and well‑defined data domains. Microservices expose business functions as composable services that AI agents and orchestration platforms can call, turning domains like billing, pricing or fraud detection into reusable skills for intelligent automation.
As enterprises accelerate AI adoption, architecture decisions increasingly influence AI feasibility. Modern AI systems rely on API-driven access to domain services, clean data boundaries, and modular business capabilities. Monolithic architectures often make AI integration difficult due to tightly coupled data models and limited modular access points.
Microservices, when designed correctly, provide API-first interaction models, clearly defined domain ownership, and independent data sources. This allows, for example, a recommendation engine to consume product and order events independently, or fraud detection models to integrate directly with payment services.
The 2026 concept: Agentic AI
In an Agentic enterprise, AI agents (like those built on AWS Bedrock or OpenAI) act as the orchestrators. A well-designed microservice with a clean, versioned API is essentially a skill that an AI agent can call to perform a task.
If your billing logic is buried in a monolith, an AI agent cannot learn to use it. If it is a microservice, the AI can orchestrate it to handle complex customer support refunds autonomously.
AI readiness is less about algorithms and more about architectural flexibility. Enterprises that design for modularity today are better positioned to layer intelligence tomorrow.
When not to move to microservices
Microservices are not automatically the right choice for every system. Small applications with stable roadmaps, limited team sizes, and modest scale often benefit more from a modular monolith. They can then avoid the operational overhead and distributed complexity that microservices introduce.
Microservices are not universally appropriate. In certain scenarios, adopting microservices may introduce unnecessary complexity. Organizations should reconsider migration when:
- The application is small and unlikely to scale significantly
- The team lacks DevOps automation maturity
- Infrastructure monitoring is limited
- Domain boundaries are unclear
- The business roadmap is stable and unlikely to evolve
The two-pizza rule for architecture decisions
In these cases, a well-structured modular monolith can deliver simpler operations, faster development cycles, and lower infrastructure overhead. A good rule of thumb is the two-pizza rule.
If your entire engineering team can be fed with two large pizzas, you do not need microservices. You need a well-organized monolith. Microservices are a solution for organizational scaling, not just technical scaling.
Architecture decisions should reflect business trajectory, not industry momentum. Strategic restraint often builds more trust than aggressive modernization.
Microservices adoption reality check in 2026
Industry articles and case studies in 2025–2026 report that many so‑called microservices deployments behave as distributed monoliths: tightly coupled services, shared databases, and complex synchronous call graphs.
Teams are responding with stronger domain‑driven design, observability via OpenTelemetry, and a renewed interest in modular monoliths when team size and complexity do not justify full microservices.
The 2026 architectural quality gate: your final exam
Before promoting new services to production, mature teams use architectural quality gates to verify autonomy, fault tolerance, observability, data ownership, and cost transparency. These checks distinguish professional microservices ecosystems from distributed monoliths and help ensure that modernization actually reduces risk and complexity over time.
To deliver on the promise of a reality check, here are the five non-negotiable standards that distinguish a professional microservices ecosystem from a chaotic distributed monolith. Before any new service is promoted to production, it must pass these five gates.
01. Can this service be deployed, rolled back, and scaled without a coordinated release train involving other teams?
The 2026 standard: Use Contract Testing (e.g., Pact) to ensure the service adheres to its API promises without needing other services online during the build.
02. If this service’s primary dependency goes offline, does this service stay alive?
The 2026 standard: Implementation of Graceful Degradation. Every external network call must be wrapped in a Circuit Breaker pattern. If a dependency fails, the service should return a cached or default response, not an error.
03. Can a developer trace a single user request across the entire system without logging into five different servers?
The 2026 standard: Every service must inject and propagate Trace IDs using the OpenTelemetry (OTel) standard. A service health dashboard must exist before launch, showing SLIs like latency percentiles (p95, p99) and error rates.
04. Does this service own its data, or is it sharing a database with the legacy monolith?
The 2026 standard: Use the Outbox Pattern to ensure that database updates and event messages (to Kafka/SQS) are treated as a single atomic transaction. No direct database access from other services.
05. Do we know exactly how much this service costs to run per 1,000 requests?
The 2026 standard: Integrate Cost-as-a-Metric into the dashboard. Every cloud resource must be tagged with the service name, allowing the team to see the financial impact of code changes in real-time.
At Wishtree, we approach microservices transformation as a structured modernization journey, and not a technology replacement exercise. Our goal is to create resilient, AI-ready, scalable platforms that align with long-term business strategy. Because modernization should reduce complexity, not redistribute it.
The Wishtree partnership: your guide through the microservices maze
Microservices architecture offers enterprises a pathway to accelerated feature delivery, improved resilience, independent scalability, and AI-ready platform design. However, success depends on disciplined implementation. Without domain alignment, governance, and observability, microservices can introduce distributed complexity instead of agility.
Industry experience in 2026 shows that teams who combine domain‑driven design, observability, and clear ownership are far more likely to realize the promised agility and resilience benefits of microservices than those who treat them as a purely technical re‑platforming.
With the right strategy, rooted in domain-driven design, phased migration, and operational maturity, microservices become a foundation for sustainable digital transformation.
Microservices done right do not just modernize applications. They modernize the enterprise operating model.
Wishtree guided dozens of enterprises through this transition, and we have learned that success leaves clues…and so does failure.
Our engagement typically includes:
- Domain discovery and capability mapping
- Architecture readiness assessment
- Migration roadmap design
- Strangler-based implementation
- Observability and governance setup
- Cloud-native and Kubernetes orchestration
- DevOps pipeline enablement
At Wishtree, we help you evolve intentionally. Let us start the conversation. Contact us today!
FAQs
What is the single biggest mistake companies make when adopting microservices?
The biggest mistake is starting with technology instead of domain boundaries. Teams often split a monolith into frontend and database services instead of business capabilities like Payments or Inventory. This creates a distributed monolith – multiple services, but all tightly coupled, with none of the autonomy that microservices are supposed to provide.
How do I know if my organization is ready for microservices?
Ask yourself three questions:
(i) Do we have clear, stable business domains we can model?
(ii) Does our engineering team have DevOps maturity, including CI/CD and automated testing?
(iii) Is our organization structure aligned with the Inverse Conway Maneuver – can we organize teams around business capabilities?
If you answered “no” to any of these, focus on readiness before migration.
How long does a typical microservices migration take?
Using the Strangler Pattern, you can extract your first service in 8-12 weeks and deliver business value immediately. A full enterprise transformation may take 18-36 months, depending on the size and complexity of your legacy estate. The key is incremental delivery, not a multi-year rewrite.
Will microservices not increase my infrastructure costs?
Initially, yes. You will be running more services, which means more containers, more network traffic, and more monitoring. However, well-designed microservices enable selective scaling.
Instead of scaling your entire monolith during peak demand, you scale only the services under load. Over time, this leads to significant cost optimization (FinOps).
How do microservices help with AI adoption?
In 2026, AI agents need clean, modular APIs to act as skills. A monolith is a black box to an AI. It is difficult for an agent to understand and call specific business functions. A microservices ecosystem, with its well-defined domain APIs, becomes a library of capabilities that AI agents can orchestrate autonomously. AI-readiness is an architectural feature.
What is OpenTelemetry, and why should I care?
OpenTelemetry (OTel) is the industry standard for observability – tracing, metrics, and logs.
In a distributed system, a single user request may travel through 10-20 services. With OTel, you can trace the entire request path, identify latency bottlenecks, and reduce Mean Time to Resolution (MTTR). In 2026, OTel is not optional, but the price of admission for distributed systems.
Should we use Kubernetes?
Kubernetes is a powerful orchestration platform, but it is not synonymous with microservices. You can have microservices without Kubernetes (using serverless or PaaS), and you can have Kubernetes without microservices (running a monolith in a container).
At Wishtree, we recommend Kubernetes when you need automated scaling, service discovery, and self-healing at scale. But we also help you assess whether the operational overhead is justified for your use case.
What is the difference between a modular monolith and microservices?
A modular monolith is a single deployment unit with clean internal module boundaries (separate packages, well-defined interfaces).
It offers many of the organizational benefits of microservices, such as team ownership and clear boundaries. But without the network complexity.
It is an excellent starting point for small-to-mid-sized teams. You can always break out modules into full microservices later when scaling demands it.
How do you handle database migrations in a microservices architecture?
This is one of the hardest parts of the transition.
The rule is Database-per-Service. It requires a distributed data architecture where data ownership is clear, consistency is managed through patterns like Saga, and migration strategies protect existing business operations.
During migration, you must decompose the monolithic database carefully. This often involves:
(i) identifying which tables belong to which bounded context,
(ii) creating seams in the database,
(iii) migrating data to new service-specific databases, and
(iv) using Anti-Corruption Layers to keep old and new systems in sync during the transition.
When should I merge two microservices back together?
This is a brave and wise decision, according to team Wishtree. If two services are so tightly coupled that they always change together, have high chatty communication, or share data models extensively, they belong in the same module. Do not be afraid to un-distribute your monolith to regain sanity.



